首页 › 论坛 › 置顶 › 使用Python和OpenCV从图像中提取和保存字符
-
作者帖子
-
2025-04-11 11:15 #14702Q QPY课程团队管理员
通常情况下,当我们想要从图像中提取文本时,大家可能会想到 Google Translate,它可以上传图片或用手机摄像头拍照,然后就能得到翻译结果或想要的文本。然而,今天我们将带您了解其背后的工作原理,但在这篇文章中仍然只是一个小的切入点,距离 Google Translate 的工作机制还有一定的距离。
好的,那我们就开始吧。在这篇文章中,我们将讨论图像处理(Image Processing)和 OpenCV 的技术,这些大家可能已经有些耳熟能详。我们将利用这些技术将图像中的字符分离成单个字符的小图像,然后将每个字符保存为单独的图像文件,这是进行光学字符识别(OCR,Optical Character Recognition)工作的重要基础。
那么我来补充一下 OCR 的相关说明:光学字符识别(Optical Character Recognition,简称 OCR)是一个机械或电子过程,用于将手写或打印文本的图像转换为计算机可编辑的文本。图像捕捉可以通过扫描仪、数码相机等设备完成。OCR 是识别模式、人工智能和计算机视觉领域的一个研究方向。
首先,我们需要安装库
pip install imutils这是一个用于OpenCV的Python扩展库,提供了一些便利功能,例如:
轮廓排序、图像缩放(resize)、自动旋转图像、角度/坐标转换。这将是我们此次工作的主要库。步骤 1 下载图像并转换为灰度图
import cv2 from imutils import contours image = cv2.imread('1.png') gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
我们将从加载包含文字的图像开始,并将其从彩色图像转换为黑白图像,以便于后续处理。
步骤 2 使用 Otsu 的阈值分离背景与文字
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY_INV )[1]
接下来,我们将使用 Otsu 的阈值方法来自动确定中间值,以便将背景与字符分开。我们将其设置为反转 (THRESH_BINARY_INV),以使字符为白色,背景为黑色。
步骤 3 寻找字符的边界并从左到右排列
cnts = cv2.findContours( thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE ) cnts = cnts[0] if len(cnts) == 2 else cnts[1] cnts, _ = contours.sort_contours(cnts, method="left-to-right")我们将使用 cv2.findContours() 来找到每个字符的边界,然后使用 imutils 库中的 sort_contours() 函数将它们从左到右进行排序,这适合从左到右阅读的英语。
步骤4:逐个字符裁剪ROI并保存图像
ROI_number = 0 for c in cnts: area = cv2.contourArea(c) if area > 10: x,y,w,h = cv2.boundingRect(c) ROI = image[y:y+h, x:x+w] cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI) cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2) ROI_number += 1

在每个轮廓中循环检查区域是否大于10,以过滤噪声
裁剪出包围字符的边界框
将每个图像保存为文件 ROI_0.png, ROI_1.png, …
同时使用 cv2.rectangle() 绘制绿色框,以显示结果,查看程序是否正确检测步骤5:显示结果
cv2.imshow('thresh', thresh) cv2.imshow('image', image) cv2.waitKey()显示阈值图像和带有文本框的实际图像然后等待用户按下按钮以关闭窗口
更多示例
我们将尝试使用其他图像来测试这篇关于使用Python和OpenCV进行图像中的文本分离和保存的文章是否可以在实际中使用
步骤 1 加载图像并转换为灰度图
import cv2 from imutils import contours image = cv2.imread('1.png') gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
我们将从加载包含文字的图像开始,并将其从彩色图像转换为黑白图像,以便后续处理更加简便。步骤 2 使用 Otsu 的阈值来分离背景与字符
thresh = cv2.threshold( gray, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY_INV )[1]
接下来,我们将使用 Otsu 的阈值方法来自动确定中间值,以便将背景与字符分离。我们将执行反转操作 (THRESH_BINARY_INV),使字符呈现为白色,背景呈现为黑色。
步骤 3 寻找字符的边界并从左到右排列
cnts = cv2.findContours( thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE ) cnts = cnts[0] if len(cnts) == 2 else cnts[1] cnts, _ = contours.sort_contours(cnts, method="left-to-right")我们将使用 cv2.findContours() 来找到每个字符的轮廓,然后使用 imutils 库中的 sort_contours() 函数将其从左到右排序,这适合从左到右阅读的英语。
步骤 4 按字母逐个裁剪 ROI 并保存图像
ROI_number = 0 for c in cnts: area = cv2.contourArea(c) if area > 10: x,y,w,h = cv2.boundingRect(c) ROI = image[y:y+h, x:x+w] cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI) cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2) ROI_number += 1

在每个轮廓中循环检查面积是否大于10,以过滤噪声
裁剪出包围字符的边界框
将每个图像保存为文件 ROI_0.png, ROI_1.png, …
同时使用 cv2.rectangle() 绘制绿色框以显示结果,以查看程序是否正确检测到步骤 5 显示结果
cv2.imshow('thresh', thresh) cv2.imshow('image', image) cv2.waitKey()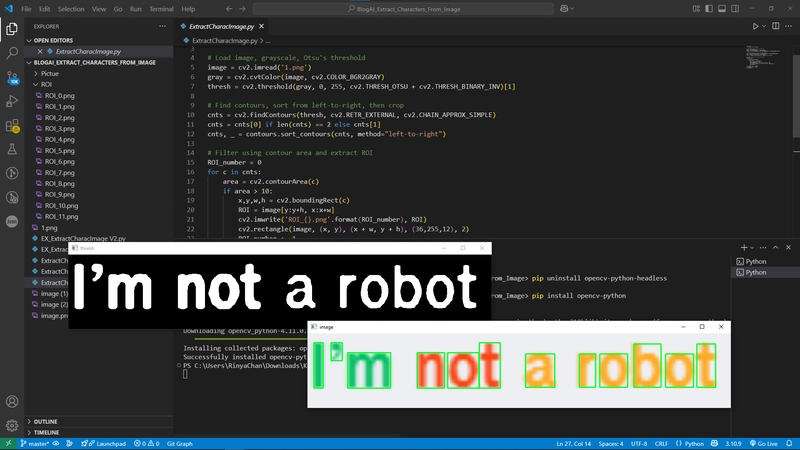
显示阈值图像和带有文本框的实际图像
然后等待用户按下按钮以关闭窗口所有代码
import cv2 from imutils import contours # 加载图像,转换为灰度图,使用大津法阈值 image = cv2.imread('1.png') gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY_INV)[1] # 查找轮廓,从左到右排序,然后裁剪 cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = cnts[0] if len(cnts) == 2 else cnts[1] cnts, _ = contours.sort_contours(cnts, method="left-to-right") # 使用轮廓面积进行过滤并提取感兴趣区域(ROI) ROI_number = 0 for c in cnts: area = cv2.contourArea(c) if area > 10: x,y,w,h = cv2.boundingRect(c) ROI = image[y:y+h, x:x+w] cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI) cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2) ROI_number += 1 cv2.imshow('thresh', thresh) cv2.imshow('image', image) cv2.waitKey()总结
在本文中,我们展示了如何使用图像处理(Image Processing)和OpenCV从图像中分离并保存字符。通过附加的示例,我们将学习如何使用OpenCV将图像转换为可用格式。
通过使用阈值和轮廓从图像中分离字符,并将字符图像裁剪并保存为子文件。该技术可以作为准备OCR系统数据的初步步骤,或者作为独立工具从图像中提取文本,也可以在后续工作中进一步扩展。参考文献
https://stackoverflow.com/questions/60515216/extracting-and-saving-characters-from-an-image
-
作者帖子
- 哎呀,回复话题必需登录。